Abstract
Reinforcement Learning (RL) often requires large number of environment interactions to generalize to unseen in-distribution tasks, particularly when policy initialization is suboptimal. Existing meta-RL and transformer-based methods adapt to unseen tasks with few demonstrations but usually require training on many tasks (usually 85% of tasks in task distribution). To address this challenge, we propose a novel framework that leverages adversarial hypernetworks to generate strong policy initializations on unseen tasks, enabling rapid adaptation with minimal interactions, even when pre- trained on as minimum as 30% of tasks. We demonstrate the effectiveness of our approach on MuJoCo continuous control tasks, showcasing strong zero-shot policy initialization and rapid adaptation on unseen tasks. Additionally, we demonstrate that our framework can be extended to Multi-Task RL (MTRL) setting, where it outperforms existing hypernetwork based methods on manipulation tasks from MetaWorld benchmark. Through rigorous experimentation, we show that our frame- work outperforms the prior competitive baselines from in- context RL and meta RL on zero-shot transfer and enables efficient adaptation to unseen in-distribution tasks.
Overview
Section 1: Zero Shot Initialization + Efficient Adaptation
Components:
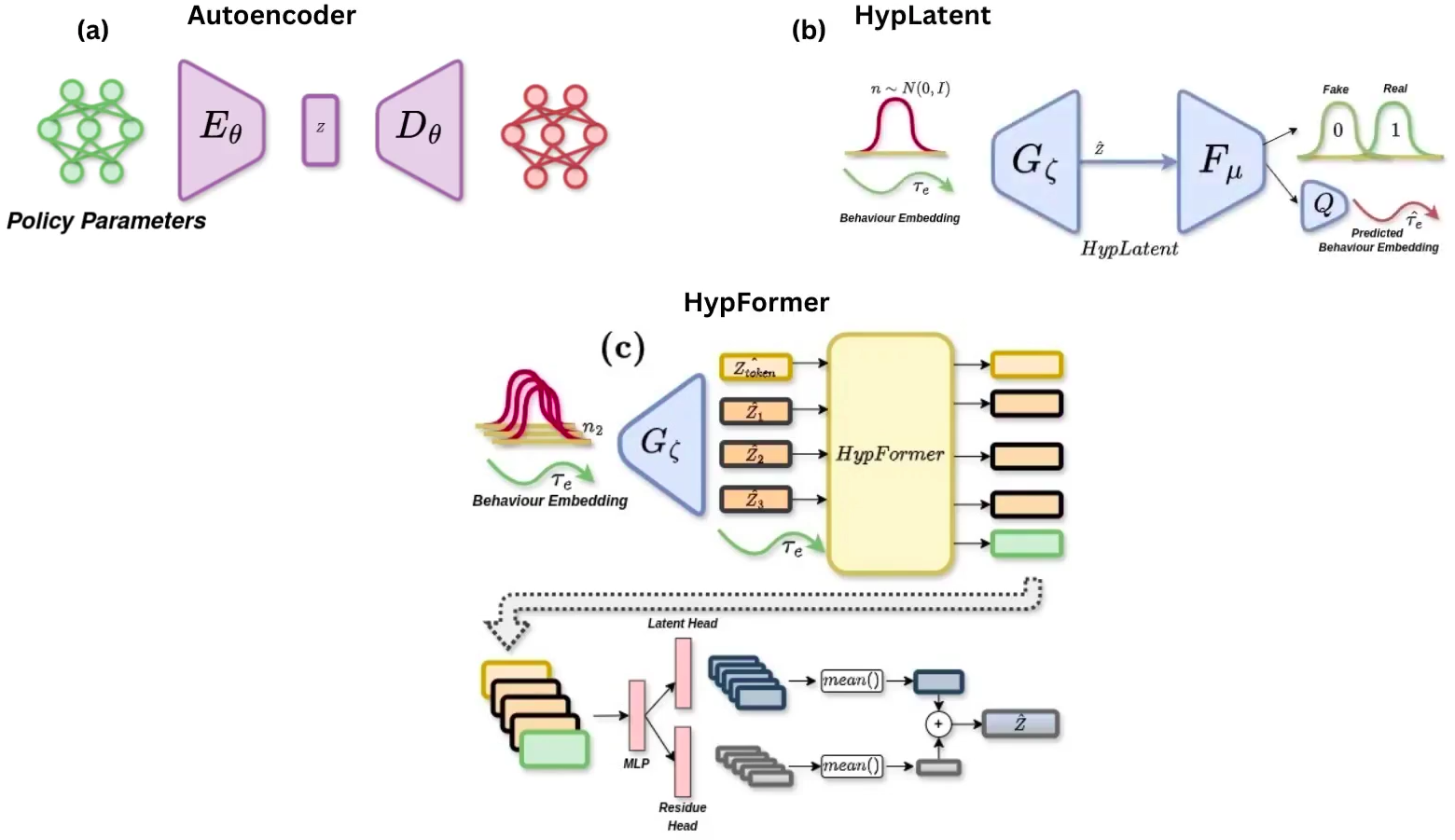
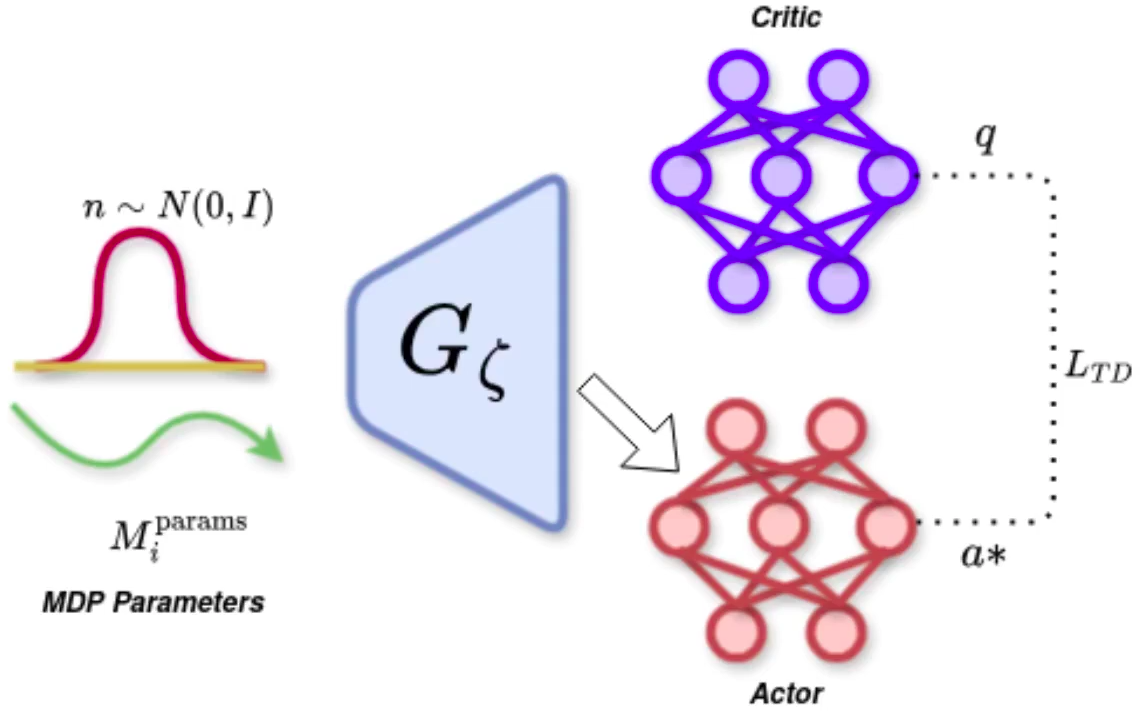
- HypLatent. An generative adversarial framework with generator trained to predict policy parameters given the MDP parameters of the given task as input. The discriminator trains in parallel with the generator to discriminate synthetic parameters from the ground truth parameters, thereby forcing the generator to learn to predict parameters closer to the ground truth.
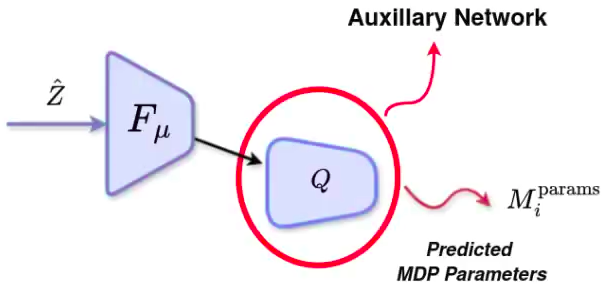
- Auxillary Network (Q). This is a neural network that learns to reconstruct the MDP parameters, given an output token from the discriminator. Through this network, we ensure that the information related to the task (represented by MDP parameters) is not lost as the network trains with time, reducing the chance of mode convergence and other associated local minima
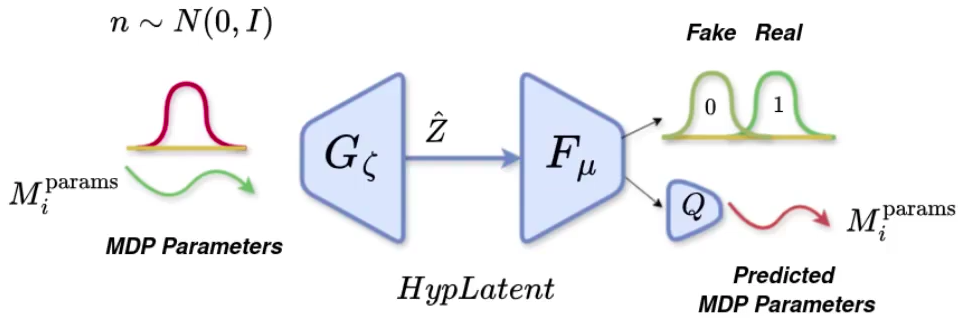
Zero-shot Policy Initialization. For a given Mujoco Continuous environment, this framework is trained on a subset of tasks. The subset size is varied from 30% to 85% of the total tasks. The trained model is then tested on unseen tasks from the same environment. We show that the generator model is able to generalize zero-shot to unseen tasks, even when trained on as minimum as 30% of tasks.
Efficient Adaptation. We propose to use TD-regularized actor-critic method to adapt the zero-shot policy to the unseen task. We show that the policy is able to adapt to the unseen task with minimal interactions.
We tested our framework on Mujoco's Hopper and Ant-Direction environments. Please refer to the paper for detailed section on experiments.
Section 2: Extension to Multi-Task RL (MTRL)
MTRL Setting. We also show that our framework, with a few changes, can be efficiently adapted to MTRL setting. In an MTRL setting, all the tasks share similar action space, but different state spaces. Similar to prior work Make-An-Agent, we assume the dimensionality of the state space for each of these tasks to be the same. Now, the goal of MTRL works, specifically, hypernetwork-based MTRL works, is to learn a common representation space for all the tasks seen during the training phase. Post-training, the hypernetwork must be capable of predicting accurate policy weights for each of the training tasks. At the same time, the hypernetwork must also be able to predict policy parameters for newer tasks when provided with their behavior embeddings.
We show that our work outperforms the prior hypernetwork-based work on tasks seen during training time. This shows that the trained framework is effective at retaining training tasks' shared representations and unshared nuances to a great extent. At newer tasks, we perform at par with the SOTA Make-An-Agent.
With additional changes such as "HypFormer" (which is further explained below, and in the paper), our work greatly improves its performance on training tasks.
Components:
- Autoencoder. For MTRL tasks, instead of directly training the generator to predict policy parameters, we choose to operate in the latent space, similar to the paper Make-An-Agent. For this, we use an autoencoder to encode the policy neural network parameters as latent embeddings. The encoder is trained to predict latent embeddings given the policy parameters, and the decoder is trained to reconstruct the policy parameters given the latent embeddings. The autoencoder is trained with a reconstruction loss and a KL divergence loss to ensure that the latent embeddings are close to a standard normal distribution.
- HypLatent. An generative adversarial framework with generator trained to predict latent embeddings of policy parameters (unlike the previous section where the generator predicted policy parameters directly). The discriminator trains in parallel with the generator to discriminate synthetic latent embeddings from the ground truth latent embeddings, thereby forcing the generator to learn to predict latent embeddings closer to the ground truth.
- Using Behavior Embeddings to Represent the Task. Unlike previous section, where each task is represented by its MDP parameters, we choose to represent the task by its behavior embeddings, as it was proved to be more efficient representation for MTRL tasks (citing Make-An-Agent). Thus, HypLatent's generator takes the behavior embedding as input, instead of MDP parameters, for MTRL tasks.
- Auxillary Network (Q). This is a neural network that learns to reconstruct the behavior embeddings (unlike the previous section, where it reconstructs MDP parameters of the task), given an output token from the discriminator. Through this network, we ensure that the information related to task (represented by behavior embeddings) is not lost as the network trains with time, reducing the chance of mode convergence and other associated local minima
- HypFormer. The policy parameters predicted by the generator/hypernetwork may not always be close to the ground truth policy embedding. To further enhance accuracy, we introduce HypFormer which performs soft-weighted aggregation, prioritizing latent embeddings that are closer to the ground truth.
- HypFormer Architecture: We introduce two MLP branches: the latent head and the residue head.
- Latent Head: Trained to predict the ground truth latent policy embedding.
- Residue Head: Learns the residual between the generator's latent policy embedding and the ground truth latent policy embedding.
- Consistency Loss: Applied to ensure consistency between the latent head and residue head.
- For a detailed explanation of individual loss terms and notations, please refer to Section V(b) of the paper.